Chaque seconde, 29 000 Go d’informations sont publiées dans le monde. Si le web a un usage principal, c’est bien de servir de support pour échanger et stocker de l’information. Ces informations peuvent ensuite utilisées par vous … ou votre entreprise. Cet article décrit la première étape pour y procéder.
Alors, ces informations, quoi en faire ?
En tant qu’entreprise, vous pourriez connaître le comportement d’achat de vos segments clients et établir des prévisions de vente solides avec des techniques de big data. En tant que particulier, vous pouvez vous renseigner de manière extensive sur un sujet particulier : c’est le travail réalisé d’un moteur de recherche. Finalement, peu importe qui vous êtes, vous allez d’abord devoir récupérer l’information de sites web.
Vous allez devoir faire du scraping de données.

Qu’est-ce que le scraping de données ?
To scrape, en anglais, signifie « gratter » en français. Scraper des données, c’est « gratter » des pages web pour stocker l’information voulue. Cela revient à copier-coller du contenu d’une page web, mais le scraping est en général assuré par des bots, ou robots, qui s’occupent de ce travail périodiquement.
Mais un bot qui ne peut pas scraper des données que d’une page web est limité. Il faut que le bot soit capable de « ramper » d’une page à une autre, de manière à pouvoir récupérer toutes les données d’un site internet. C’est bien plus rapide que de scraper page web par page web, manuellement. Le « rampage », « crawling » en anglais, est systématiquement assuré par les bots de scraping. Il s’agit de visiter une page web, récupérer ses URL internes, les mettre en queue, et visiter ensuite ces pages, et ainsi de suite.
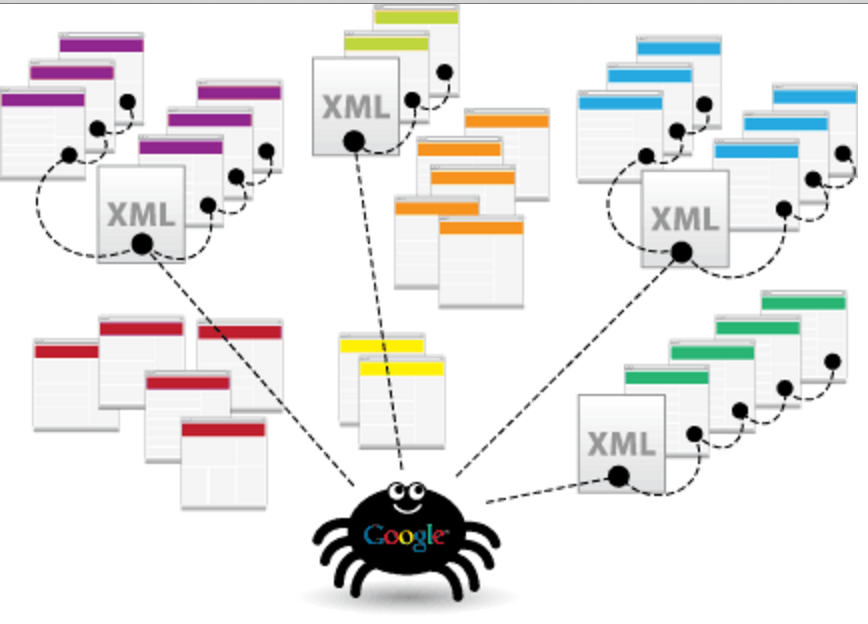
Source: http://sayonetech.com
Pour comprendre le scraping, il est nécessaire de comprendre les éléments suivants :
- Un site internet est constitué de pages web, accessibles par des hyperliens dans d’autres pages web
- Une page web est un fichier HTML retourné par le serveur, et associée à du javascript et des feuilles de style CSS. Ces fichiers HTML, .js et .css sont appelés fichiers sources.
- L’information est entièrement contenue dans la page HTML que le serveur a envoyé. Pour accéder à cette information, il faut ouvrir le fichier HTML et la chercher dans les balises (utiliser XPath ou CSS).

Un outil de scraping complet, c’est un outil qui, à partir d’un ou plusieurs sites internet, crawl de page en page en ouvrant les fichiers sources et en récupérant ce qu’on veut récupérer.
Comment scraper ?
Pour scraper des données sans avoir à coder les robots dans leur totalité, ce qui demanderait des connaissances solides en PHP (ou java / python), Javascript, HTML, CSS et XPath, nous vous proposons les trois outils gratuits suivants :

Ce site très simple mais limité est disponible gratuitement en ligne au travers de deux APIs :
- Magic : l’outil mis en vedette du site. Il permet, selon une liste d’URL de page web, de scraper automatiquement toute l’information. Celle-ci est alors disponible sous la forme d’un tableau exportable en .csv, .xlmls ou .sheets pour analyse.
- Extractor : le second outil vedette. Il permet de scraper l’information sélectionnée par clic dans un type de page web.
Ces outils sont complétés par d’autres API : Crawler et Connector, qui permet d'enregistrer sur une séquence d’action pour se déplacer le site et exécuter Extractor aux endroits voulues.
Import.io est très simple et ne demande pas de connaissances en programmation.

A l’instar d’Import.io, Kimono est très simple et ne demande pas de connaissances techniques approfondies, bien que des connaissances en HTML et javascript permettent à l’utilisateur d’aller plus loin.
Aujourd’hui, le service en ligne de Kimono n’est plus assuré. Il reste cependant la possibilité d’utiliser l’API par l’application Desktop. L’application permet de, selon une liste d’URL, extraire de l’information selon des scénarios définies au clic.
Cette manière de faire est un peu plus précise qu’Import.io. Il est aussi possible de naviguer dans la pagination d’une longue page. L’information est présentée sous forme de tableau. A l’issu de l’extraction, Kimono Desktop propose à l’utilisateur de filtrer les résultats par un script javascript écrit à la main, si voulu.
Malheureusement, avec la version Desktop, Kimono ne propose plus l’extraction de données selon des scénarios, comme le propose Import.io par « Connector » et « Extractor ».

Scrapy est un framework collaboratif and open-source pour extraire des données. Il est rapide, et facilement extensible, mais il s’adresse aux développeurs ayant des connaissances en python et connaissant XPath. Le framework possède en plus une documentation extensive pour comprendre son fonctionnement. Parmi les composants du framework – scrapy engine, scheduler, downloader, spiders, item pipeline -, seuls les spiders sont à écrire par l’utilisateur.
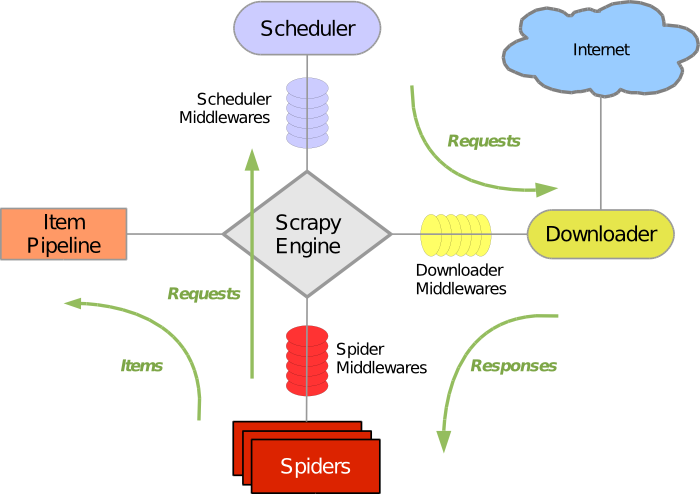
Les spiders sont des scripts appelant les différents composants qui spécifient où scraper les données, quoi scraper et comment le faire.
Les données, sous la forme d’item, peuvent être exportées sous un format spécifique avec un peu de programmation.
Scrapy est donc un excellent outil pour scraper des données, quoiqu’il s’adresse à des utilisateurs avancés.